What is a multi-tier software architecture?
A multi-tier (or "n-tier") software architecture is a way to organize your client-server software into different layers, each with a specific role. The idea is to de-couple your layers, to make it easier to maintain your application.
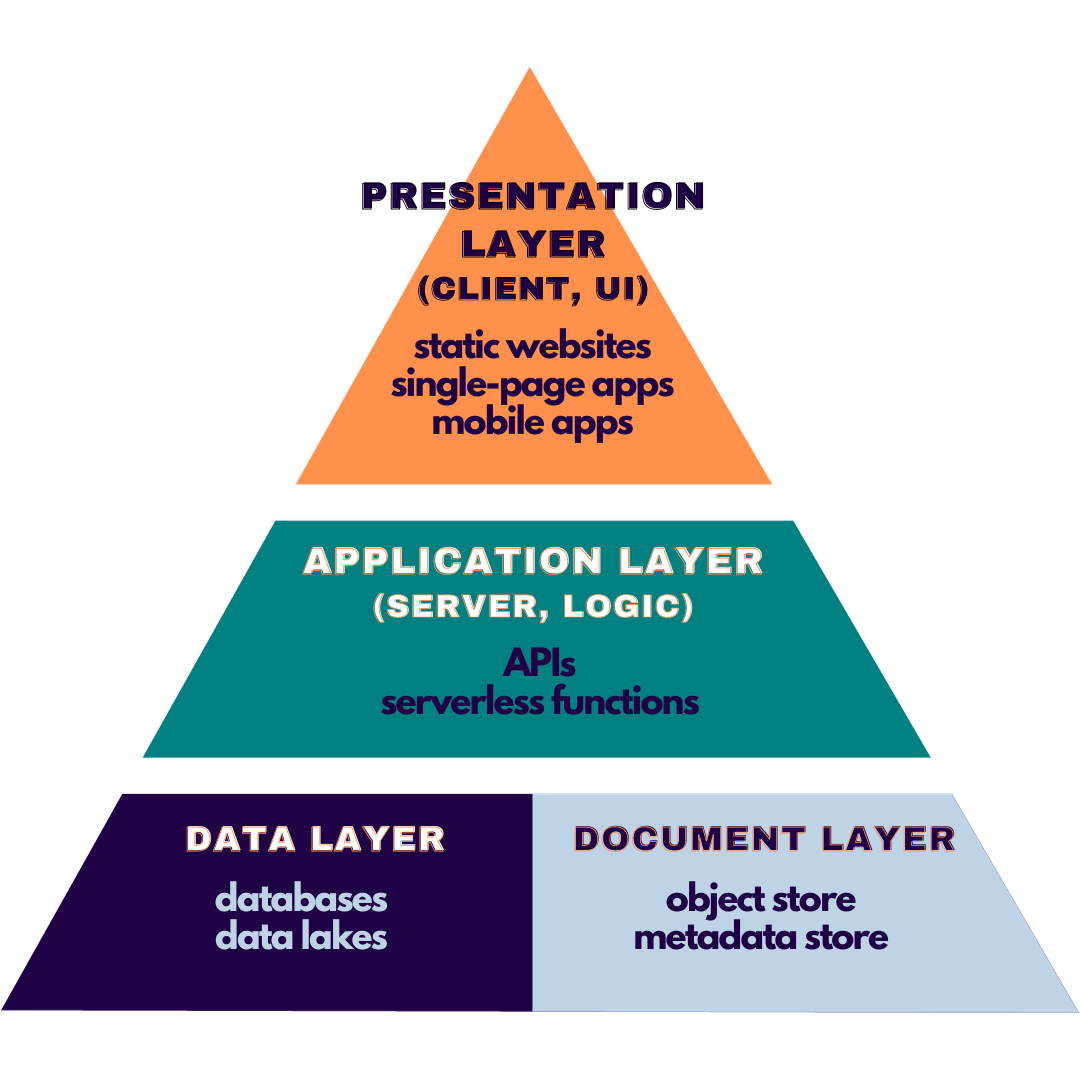
The most common multi-tier architecture is the three-tier model:
-
Presentation Tier (or Layer):
where the user interacts wiht the software, such as a website or mobile app
-
Application Tier (or Layer):
where you find the software's logic and processing
-
Data Tier (or Layer):
where the necessary data is stored
Some other examples of multi-tier architectures are two-tier, where the user interface and logic are combined, with the database being kept segregated, and the two-and-a-half-tier, where it's the application and database are combined and the presentation layer is kept separate. As well, some n-tier architectures may split the application from the business or domain logic, creating a four-tier design.
What about documents?
In tiered architectures mentioned above, it's not always clear where documents should go.
Documents as database blobs
Unlike structured data, documents (which includes both binary assets and many types of unstructured data, like JSON) are not easily stored in a relational database. In addition, search, retrieval, and analysis are not straightforward and consistent, especially when documents are not all in the same format. Nonetheless, many system designs add documents into the relational datastore, often as blobs with some additional columns for storing related metadata.
Documents as raw data
Though most documents are considered unstructured (though not all), they are not well-suited to be stored as raw data in data lakes. Data lakes are extensive repositories of raw and unprocessed data, whether that data is structured, partially structured, or unstructured; they are not meant for easy searching or real-time retrieval, since that level of performance would generally be cost-prohibitive due to the repository's size, the absence of accompanying metadata, and a lack of overarching structure.
Documents in data warehouses
Though data warehouses may be able to support more structured documents by leveraging that structure for querying and reporting, and enforcing some data integrity, they are less effective in dealing with unstructured documents and can be costly to maintain.
Documents have specific characteristics that merit separate treatment
In general, documents are a combination of an object's content (whether binary data, such as images, or plain-text data) and its metadata, i.e., information about the document's properties, attributes, and context. Rather than storing documents as blobs + metadata in a relational database, or as raw objects without their metadata in a data lake, documents should be stored using a combination of both an object storage mechanism and a metadata storage mechanism.
This will allow the document to be stored, processed, discovered, and retrieved in the most scalable and efficient manner possible, by enabling the complete utilization of both the document's content and its metadata.
This is the document layer.